LeetCode每日一题,140. WordBreakII
先看题目描述
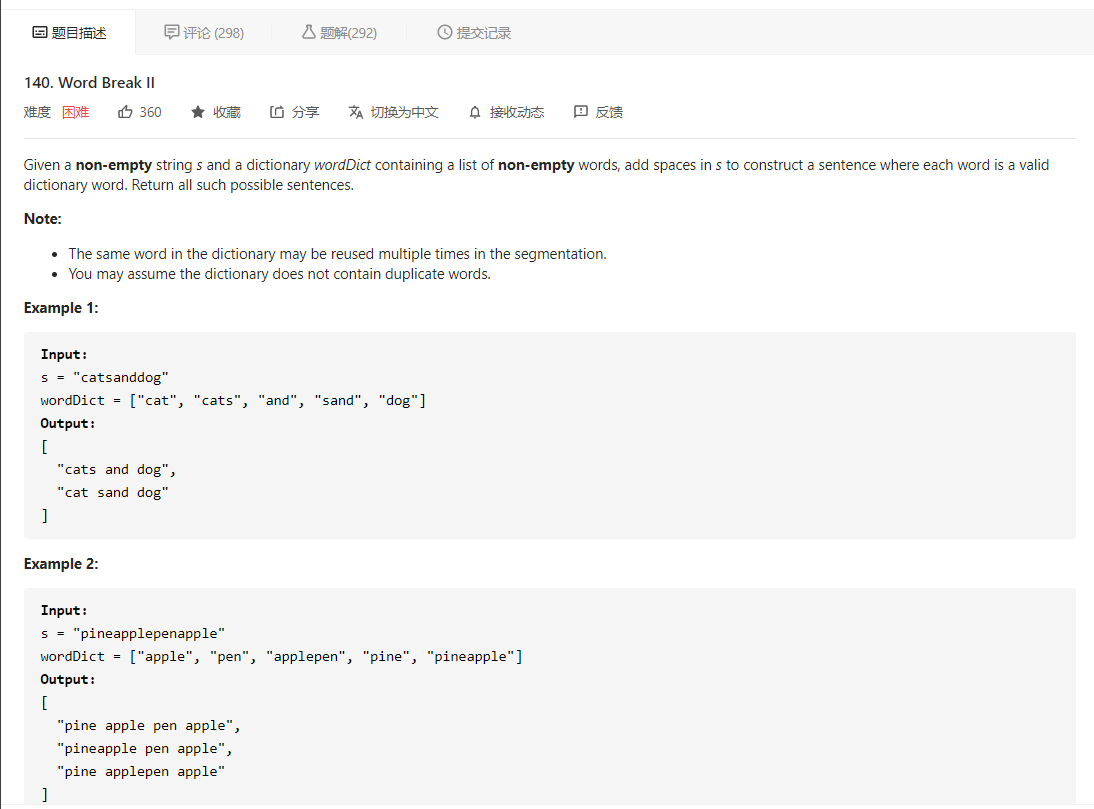
大意就是给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子
算法和思路
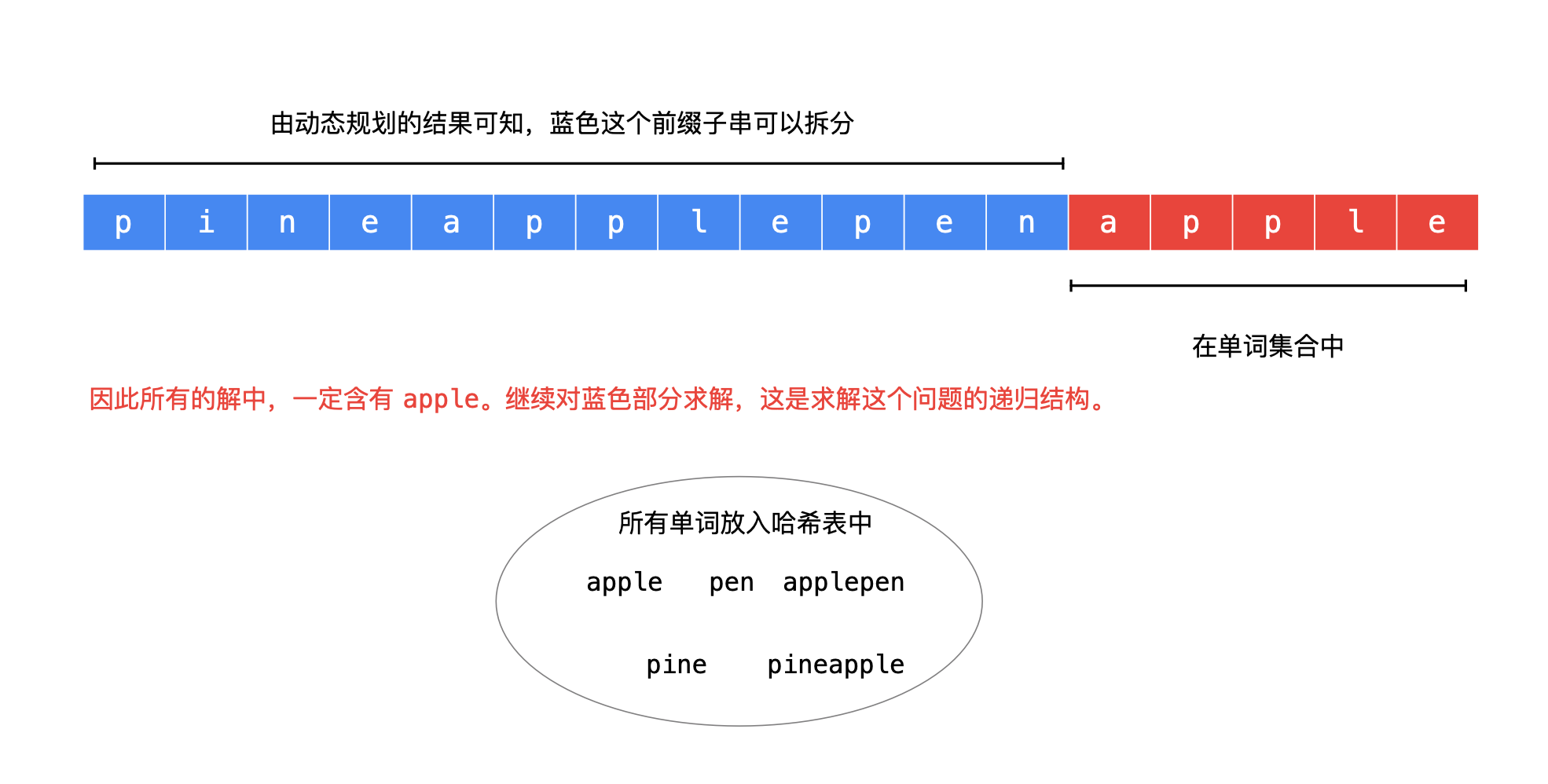
- 我们先通过动态规划得到原始输入字符串的任意长度的 前缀子串 是否可以拆分为单词集合中的单词;
- 动态规划得到的数组可以帮助我们快速评估是否有解,例如 dp[i] 为 true 就代表 s[0, i - 1] 前缀子串可以被拆分为单词集合中的单词
所有任意长度的前缀是否可拆分是知道的,那么如果 后缀子串在单词集合中,这个后缀子串就是解的一部分,例如:
根据这个思路,可以画出树形结构如下
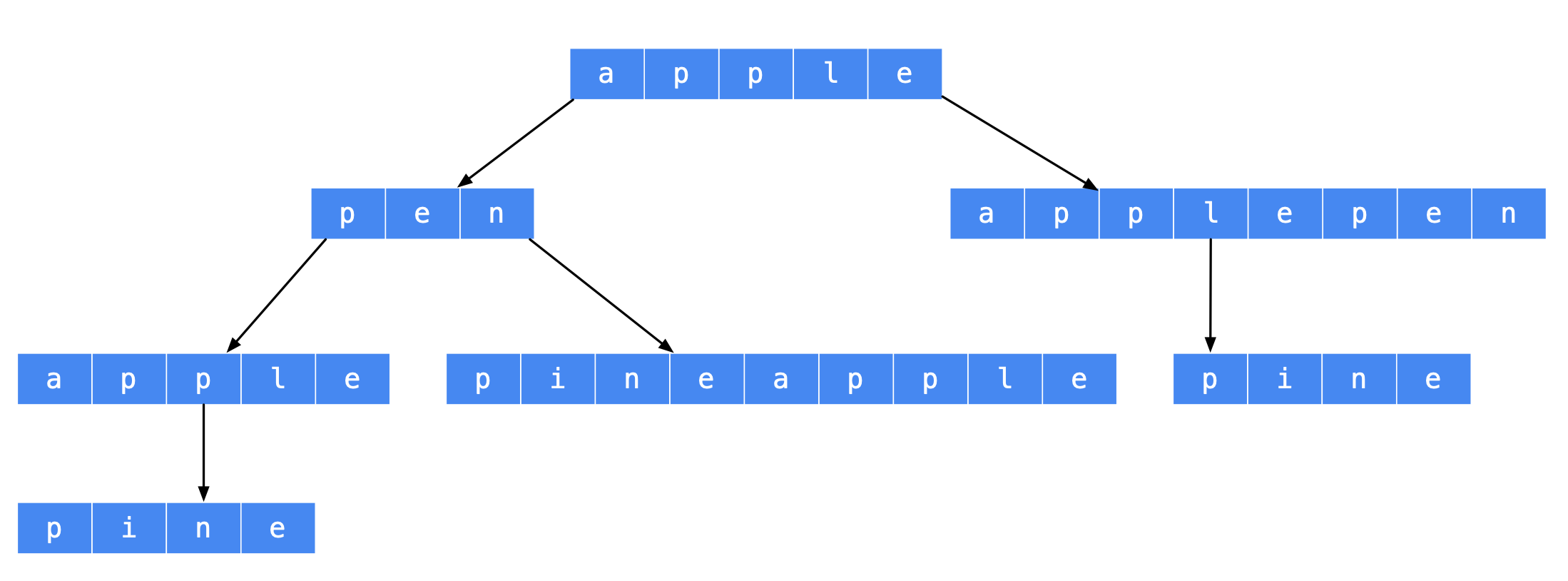
我们可以发现,树形结构中,从叶子结点到根结点的路径是符合要求的一个解,与以前做过的回溯算法的问题不一样,这个时候路径变量我们需要在依次在列表的开始位置插入元素,可以使用队列(LinkedList)实现,或者是双端队列(ArrayDeque)
算法源码
回溯+动态规划剪枝
1 | import java.util.*; |
实际上上面代码的 dfs 过程中不加 dp[i] 也是可以过的,这个问题中动态规划的主要作用是帮助评估是否有解来进行剪枝
这个是自己用回溯实现的代码,跑出来效率比较差,一开始没加动态规划进行剪枝,碰到没有解的用例就跑超时了,看了题解后加上了动态规划来剪枝,代码才跑通,感觉这个代码实现的还挺蠢,没想到可以把单词列表中所有单词加入到HashSet 中,还有就是看题解后才知道还有 String.join() 这个将列表中字符串拼接起来的方法,以及如果单词集合中的单词长度都不长,从后向前遍历是更快的,感觉从这题中学习到的东西还是挺多的
1 | import java.util.*; |